












Agent OrchestrationMar 13, 2026•15 min read
The Future of Agents Is Outcome Coordination (Part — II)
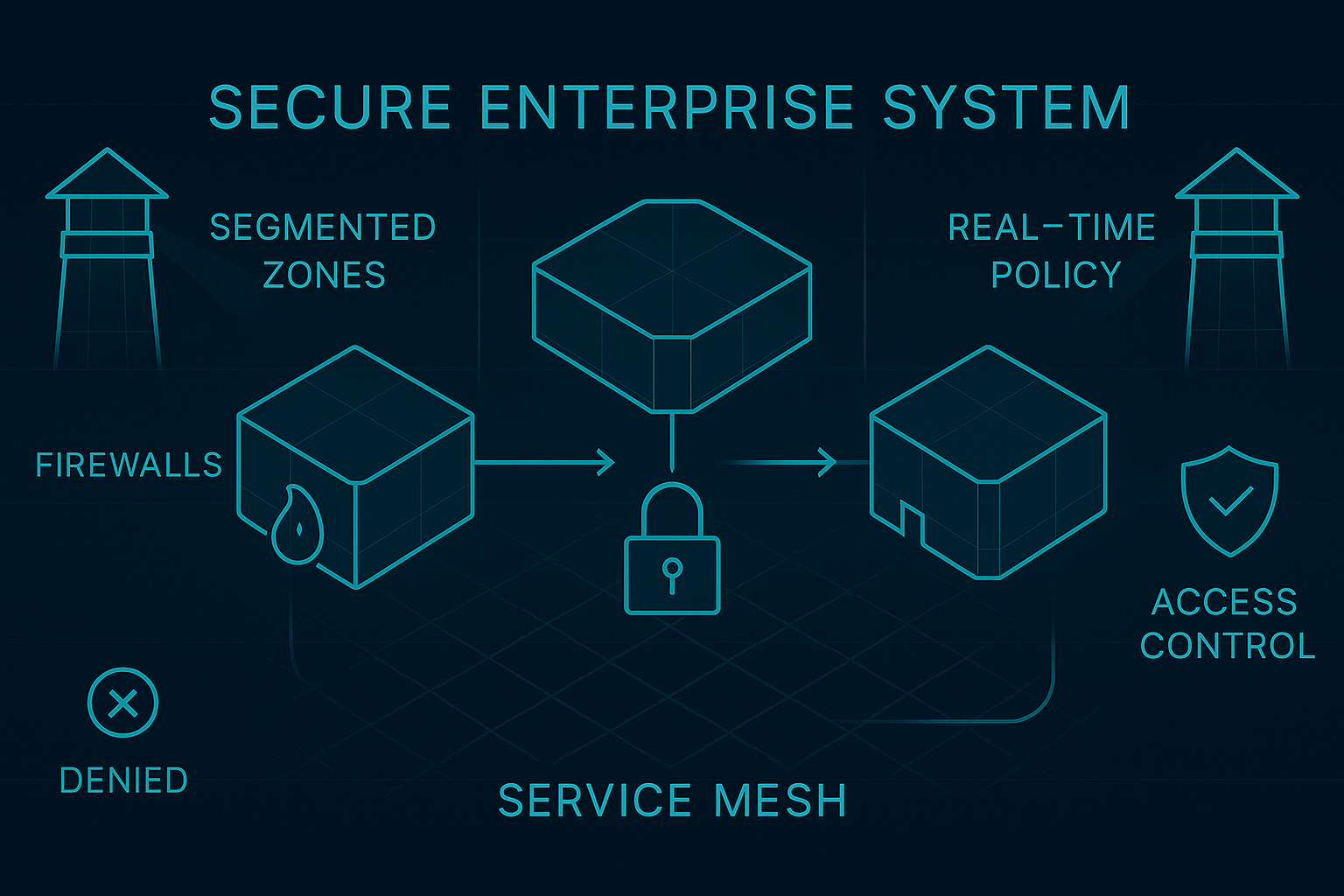
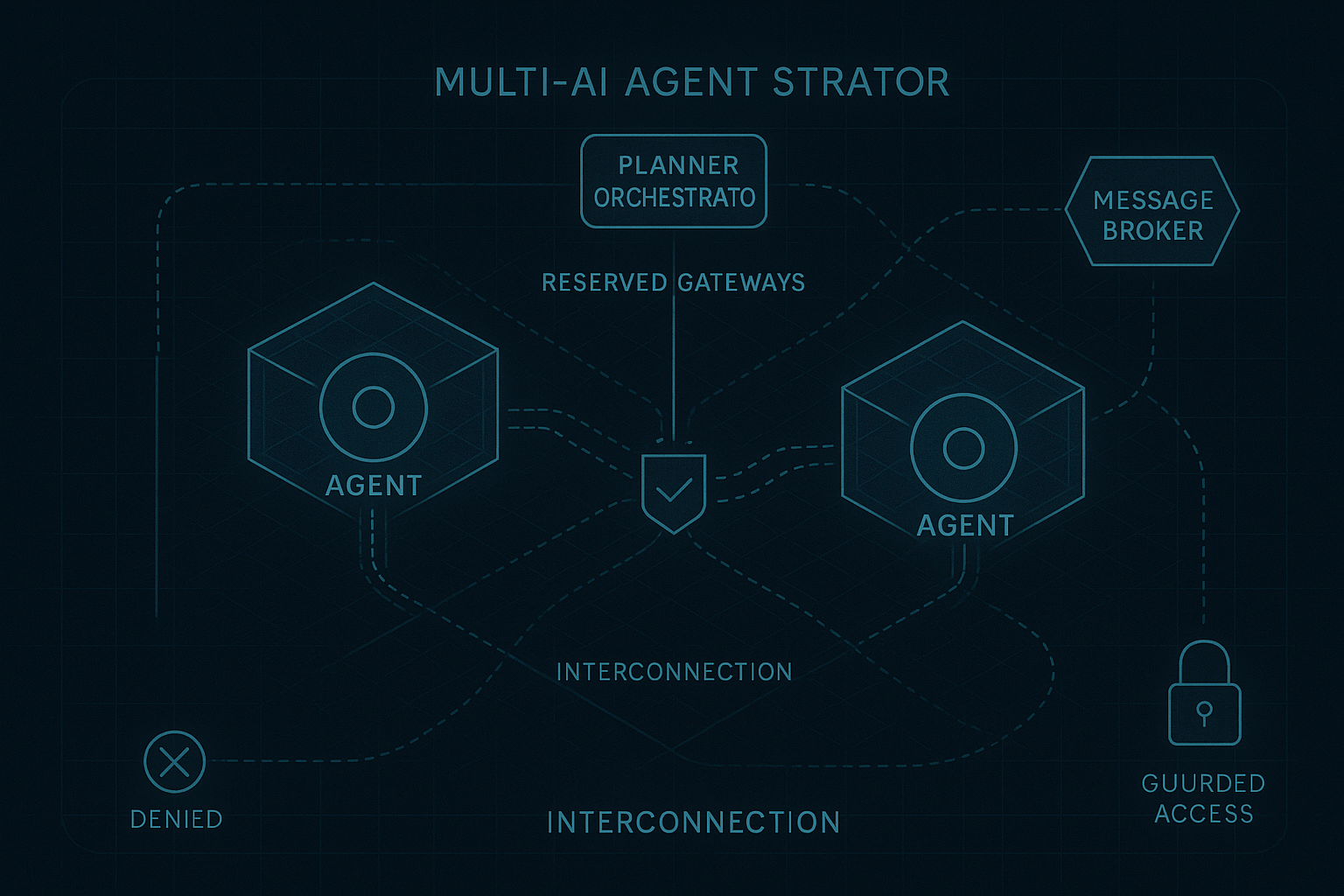
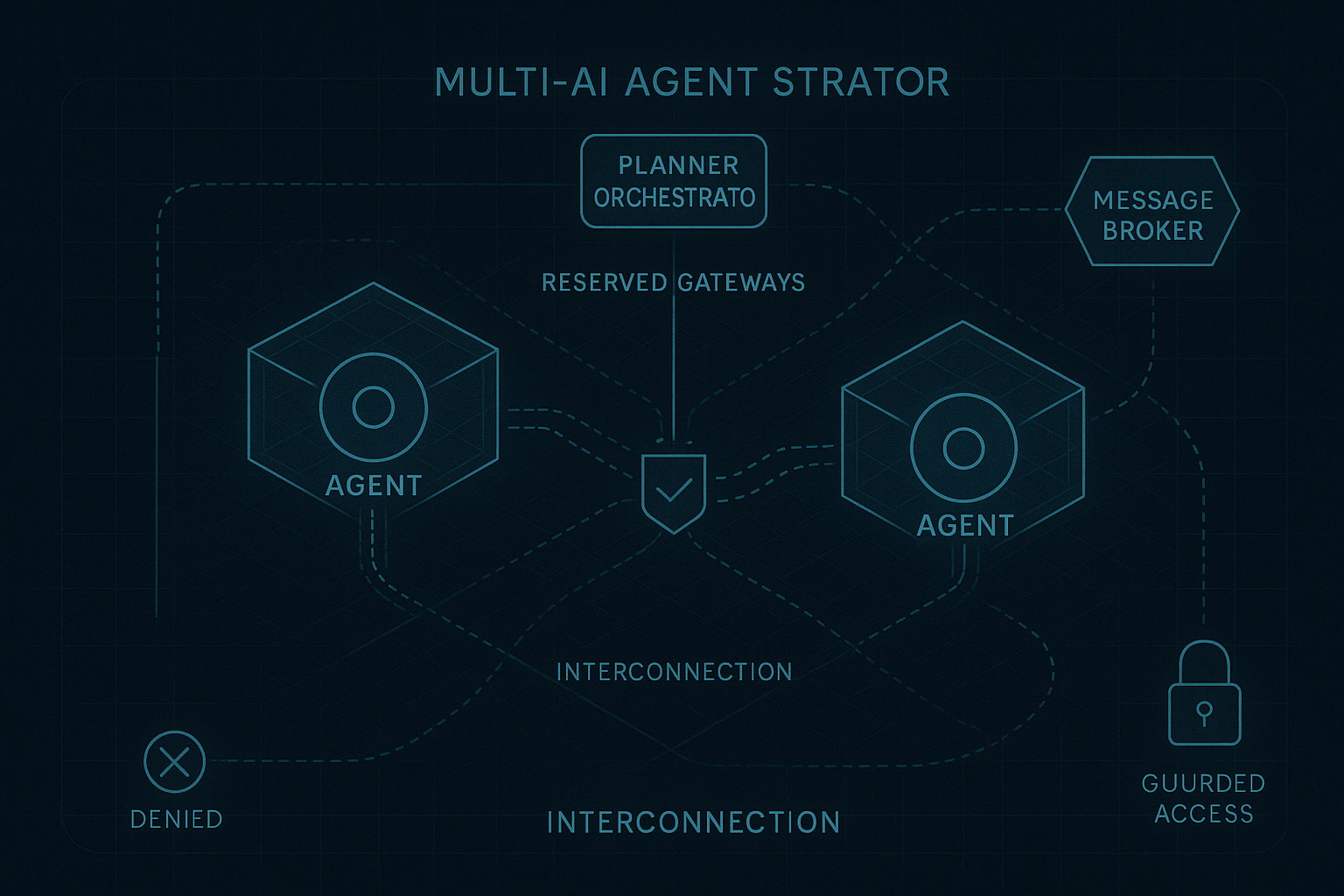
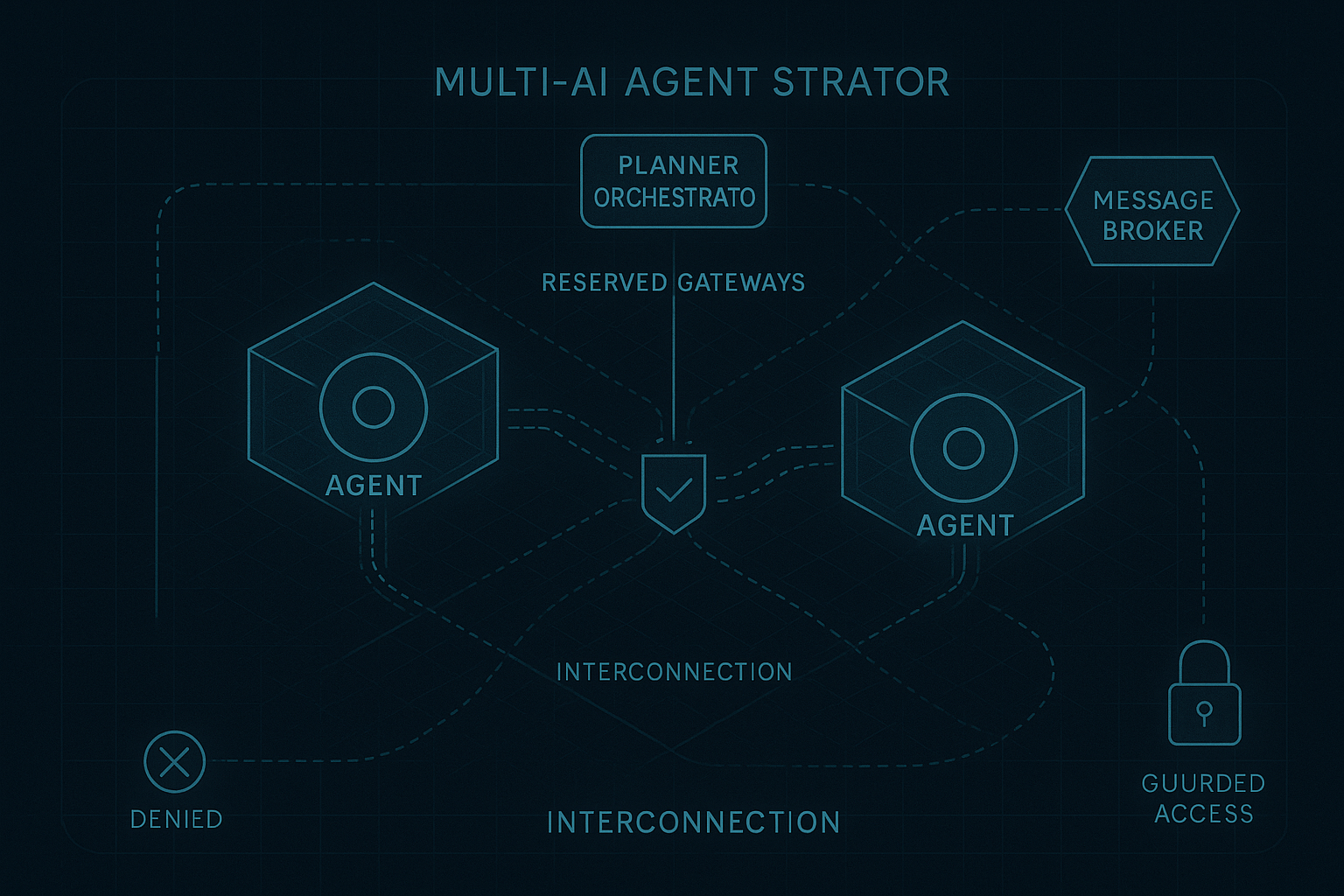
Why the next layer of the agent stack will be built on commitments, not orchestration. In the first article, I argued that the current agent stack is solving the wrong problem. We keep trying to make probabilistic systems behave like software operators: calling tools, clicking interfaces, stitching workflows, and carrying the full burden of execution.
Read More →



