How LLMs generate text
Why constraints work
An LLM generates text one token at a time. Each token is a word, a fragment, or sometimes a punctuation mark. At each step the model produces a probability distribution over its entire vocabulary and samples from that distribution to pick the next token. Then it repeats. What you see as output is a long sequence of these individual picks.
When the prompt is vague, thousands of continuations are roughly equally probable. The model samples from a wide, flat distribution, and the tokens most likely to land are the statistical average of everything similar in the training data. Safe, generic, often wrong in the ways that matter.
Constraints narrow that distribution. Every concrete detail you add — a specific format, a restriction, an example — rules out chunks of probability space and concentrates predictions on what you actually need. The length of your prompt matters much less than how many guesses you've taken off the table.
All tokens share roughly equal probability. Nothing is ruled out.
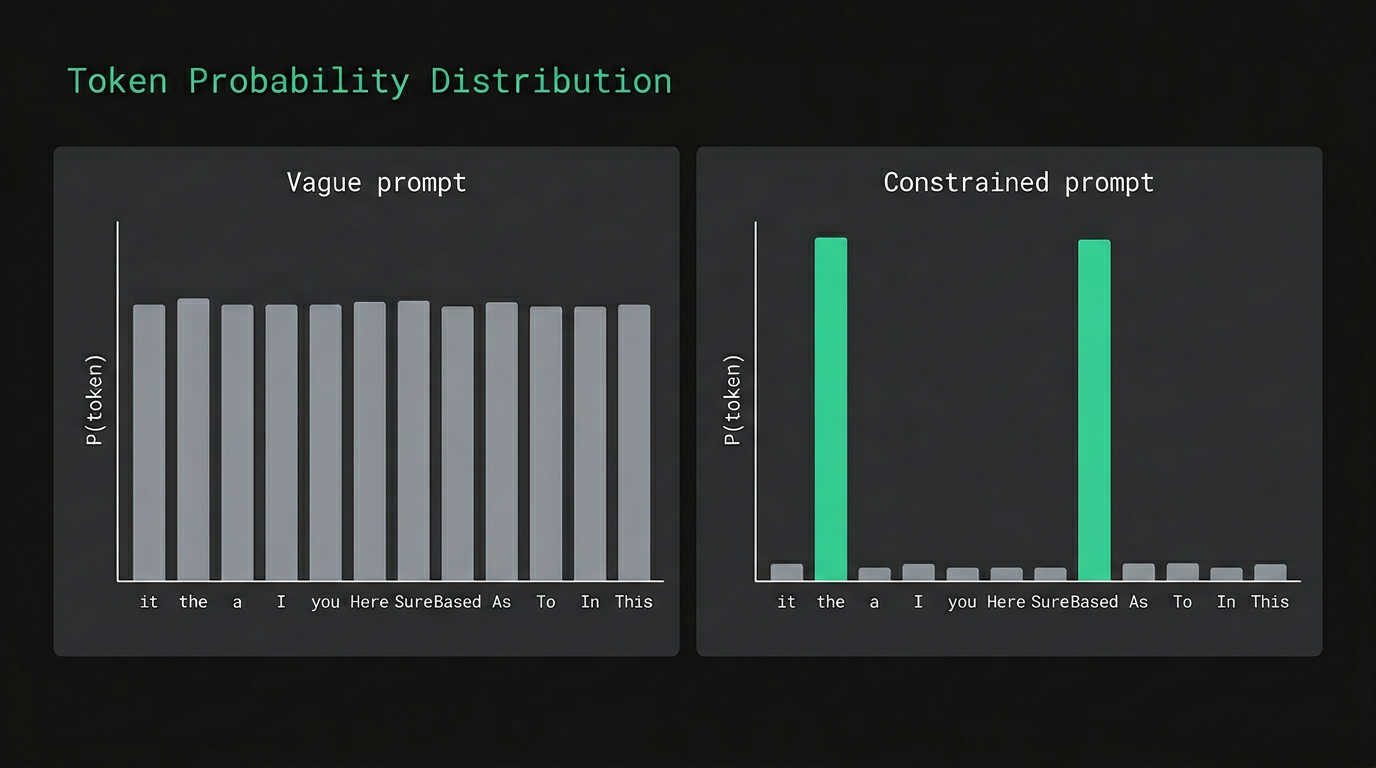
The more you constrain a prompt, the less the model has to improvise. And improvisation is where quality goes sideways.
Constraint-first prompting
Lock down the probability space
Before describing the task, give the model its working materials (which files or data to use), its limits (what to avoid, what tone to keep), and the shape of the answer you want (format, length, structure). Most of the drift you see in model output comes from leaving one of these unspecified.
Order matters more than most people expect. The model reads top-to-bottom, and early tokens set the trajectory for everything after them. Most people write the request first and add constraints at the end, because that's how conversation works. But constraints added after an open-ended request are working uphill against a direction the model has already committed to.
The GPS analogy is useful here. "Drive somewhere nice" gives the GPS nothing to work with. "42 Oak Street, avoid highways, arrive by 3pm" actually routes you. The destination matters, but so do the boundaries — and neither works without the other.
Files: design-spec.md, api-schema.json Data: last 30 days of error logs Tools: read-only filesystem access Context: Python 3.11, FastAPI, PostgreSQL

Write the constraints first. Then write what you want. The model reads your prompt in order, and the opening sets everything that follows.
Few-shot examples
Show, don't just tell
Instead of describing what you want, show it. A few-shot prompt gives the model examples of the input and the desired output before presenting the real task. The model reads the examples, picks up the pattern, and extends it to the new input. This is in-context learning: the model is completing a sequence, not being retrained.
What matters most in the examples is format, not accuracy. Label correctness is less important than structural consistency — the model is learning the shape of the task, what input looks like and what output looks like. A tidy example with approximate labels will usually produce cleaner output than a technically correct example formatted inconsistently.
Start with zero examples and add them only when output drifts. Two to five is usually enough. One thing worth trying: a negative example, showing what wrong output looks like with a brief note on why it's wrong. These are underused, and a single negative example often clarifies the task boundary better than adding another positive one.
Classify the following customer email as: complaint, inquiry, or praise. [INPUT] Email: "My order hasn't arrived in 2 weeks and nobody replied" Category:
complaint [Note: zero-shot. The model guesses the format. It might write a full sentence, use different label names, or add unsolicited explanation. No pattern was established.]
The format of your examples is part of the instruction. Inconsistent formatting across examples confuses the model about the shape of the task.
Structured input and output
Templates the model can complete
An LLM is an autocompletion engine. Give it a labeled template and it will complete the template. When the input is unstructured, the model has to decide what to say and how to organize it at the same time — two separate concerns competing for the same generation budget. With structure, the organization is settled before generation starts, so the model can put everything into content quality.
Structured input means labeled fields. "Project: X. Goal: Y. Constraint: Z." instead of a paragraph of prose. Labels tell the model how to weight different parts of the input — what is context, what is the task, what is a limit. Structured output pins the response to a format you can reliably parse or display.
For programmatic use, JSON works well, but "return JSON" is rarely specific enough. Give the model the full schema: the exact keys, types, and nesting you expect. Most LLMs can follow a concrete schema definition well enough to build a parser around the output.
I need help with a bug in my payment service. It keeps throwing a timeout exception when the order total is over $500. It worked fine last week but now it's happening all the time. I'm using Stripe's API and I think maybe the webhook is the problem but I'm not sure. Can you help me figure out what's wrong?
This could be a few things. Stripe webhooks have a 30-second timeout, and if your server isn't responding fast enough, it might be failing silently. You should also check your payment processing logic and make sure you're handling large orders correctly. It's also possible that the issue is related to your database queries taking longer for higher-value orders, or perhaps a third-party service you're calling is...
Structured output isn't just cleaner. It removes an entire class of prompt failures — the ones where the model gives you the right answer in the wrong format.
Delimiters and sections
Help the model know what is what
Without clear boundaries, the model can confuse your background information with your instructions. A long context block at the start looks like text to complete, and the model may start "finishing" your context paragraph instead of executing the task that follows. Explicit separators between context, task, and format tell the model where one type of input ends and another begins.
The exact delimiter doesn't matter much. Triple dashes, XML tags, or === all work fine. What matters is picking one and using it consistently. The failure mode is switching formats partway through a longer prompt, or forgetting the delimiter on a section where the model's attention starts to drift.
For agents, delimiters also help with prompt injection. When a retrieved document gets injected into context, it might contain text that looks like an instruction. A clearly labeled section boundary makes it easier for the model to keep "data from retrieval" separate from "instruction to follow." It doesn't eliminate the risk entirely, but it narrows the attack surface.
You are analyzing a Node.js payment service. The codebase uses Stripe API v3 on Node.js 20. The team follows TypeScript strict mode. Deployments run on AWS ECS with a 30-second health check. Identify the root cause of the timeout exception that occurs on orders over $500. Do not suggest fixes yet. Return: root_cause (one sentence), evidence (2-3 points), confidence (low / medium / high)
— undivided. model may misread where context ends and task begins.
Delimiters are a communication protocol between you and the model. They tell the attention mechanism where one type of information ends and another begins.
Context compression
Dense beats long
There are actually two distinct problems here, and it helps to understand each separately before thinking about fixes.
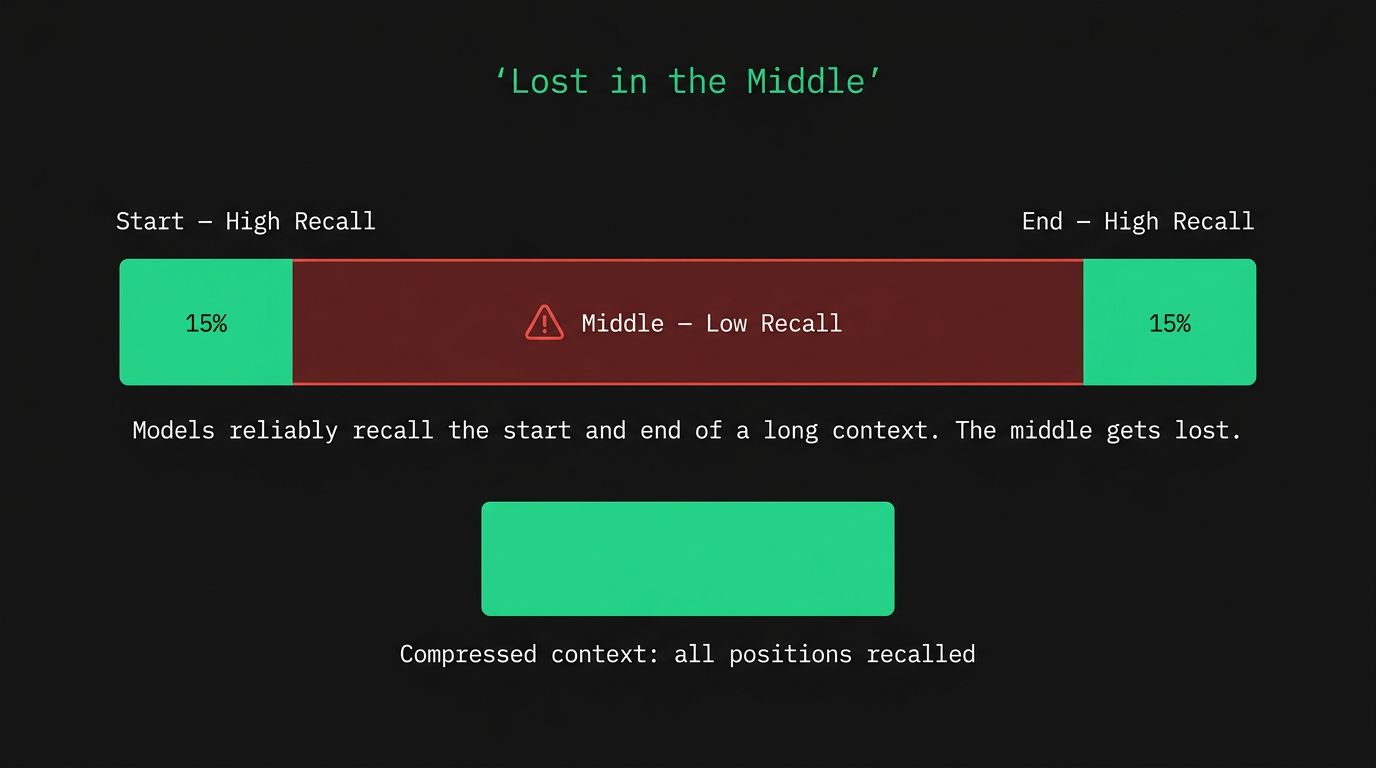
The first is the "lost in the middle" effect: an empirically documented finding that when information is placed in the middle of a long context, retrieval accuracy drops. Models consistently recall what's at the start and what's at the end. Most of what's in between becomes unreliable, and the effect gets more pronounced as context length grows.
The second problem is more fundamental. Self-attention works by computing weights across all tokens and normalizing via softmax. With 128K tokens in context, the average attention weight per token is 1/128,000. In practice the distribution is highly skewed — the model concentrates most of its weight on the system prompt, the most recent turns, the current task, and tokens that are explicitly referenced. Everything else gets close to zero. The total context window and the effective context where attention actually concentrates are two different numbers. Think of it as the difference between RAM and L1 cache: the model may technically have 128K of RAM, but the actual working set where processing happens is much smaller.
The practical takeaway is that "fits in context" doesn't mean "will be attended to." Compress information before injecting it. Put the most important content at the start or immediately before the task. Keep your context block dense: one line per decision, one line per constraint. The model needs your conclusions, not the chain of reasoning that produced them.
As context length increases, the zone of low recall expands outward from the center. Drag the slider to see how a longer document pushes important content into the dead zone.
drag to increase document length — watch the low-recall zone expand
Project: payment-service (Node.js 20 / TypeScript / Stripe v3) Objective: fix webhook timeout on orders >$500 Decided: root cause is fraud check latency (35s avg vs 30s limit) Blocker: fraud check tightly coupled to webhook handler Definition of done: webhook returns 200 in <5s, fraud check runs async Constraint: no new dependencies, stay in existing AWS ECS setup
Total context window is what the model can process. Active context is where attention weight actually concentrates. These are different. Drag the slider to see how filling up the window with more content pushes RAG results and older history into low-attention zones.
A 128K context window filled with the wrong 100K tokens is worse than a 20K window with the right 20K tokens. Fits in context does not mean will be used.
Primacy and negative instructions
Front-load and fence off
The opening tokens of a prompt carry disproportionate weight. What the model reads first frames everything that follows, and that framing is much harder to override with constraints added later. If you open with an open-ended request, the model has already picked a direction before it reads your restrictions. The practical fix: put the important constraints at the top, before the task description.
Negative instructions work by lowering the probability of specific token sequences. LLMs are biased toward their most common training patterns — phrases like "leverage synergies" show up constantly in business text, so the model gravitates toward them by default. A negative instruction suppresses that tendency directly. The vague version ("don't be generic") doesn't help much because it doesn't name a specific token sequence. The concrete version ("do not use the words 'leverage' or 'synergy'") actually shifts the distribution.
Combine positive instructions, which tell the model what to produce, with specific negative instructions, which name the patterns to avoid. Neither alone covers everything. And put both near the front of the prompt, not buried after the task where the model has already picked its direction.
Write a competitive analysis comparing Notion, Obsidian, and Roam.task
Cover features, pricing, target audience, and integrations.
Be thorough and detailed.
Do not write a sales pitch.constraint
Do not use the word "leverage".constraint
Format it as a markdown table.output spec
Keep it under 500 words.output spec
If your constraints aren't in the first quarter of your prompt, they're working harder than they need to. Put them at the top.
One task, think first
Single objective + chain-of-thought
"Research and write and edit and format" is four tasks. Each one pulls the probability distribution in a different direction, so the model compromises — and none of the four get the attention they need. If you count more than one "and" in a task description, split the prompt.
Chain-of-thought is asking the model to reason out loud before producing the final answer. For math, logic, comparisons, or anything multi-step, this improves accuracy measurably. The mechanism is that each reasoning step constrains the next one — the model has to commit to intermediate conclusions before it can reach the final answer, rather than jumping straight to a pattern-matched response.
Two phrasings worth bookmarking. "Do not produce anything yet. Outline your approach and let me review it." — useful before any longer output where a bad plan wastes effort. "Think through this step by step before giving your final answer." — good for self-contained reasoning tasks where you want improved accuracy in a single response.
Research best practices for microservices and write a blog post and create a code example and add tests and format it for Medium.
attention budget split
# Microservices Best Practices Microservices architecture offers several advantages over monolithic design... Here's a basic example: ```typescript // basic service skeleton ``` [truncated — depth thin across all four tasks, none done well]

The model's output quality scales with how narrowly the task is defined. One thing at a time is not a limitation — it's a discipline.
Iterative refinement and chaining
Prompts in sequence
A single prompt asks the model to make many sequential decisions with no feedback loop. When something goes wrong in the opening framing, the error carries forward. Every subsequent sentence is built on a flawed foundation, and by the end of a long output the drift can be significant. Inserting a review point between prompt and output lets you catch and correct that early, before the error compounds.
Prompt chaining scales this up. Instead of one big prompt covering research, planning, and execution, you write separate prompts where each one takes the previous output as input. The second prompt gets a more focused, more constrained problem than the first. Each step has a smaller blast radius if something goes wrong, and the natural separation between phases keeps each prompt's objective honest.
Complex work tends to have different thinking modes at different stages. The exploratory phase where you're generating options is different from the evaluative phase where you're making decisions, which is different again from the execution phase where you need precision. A single session trying to hold all three tends to produce muddled output in each.
Generate 5 angles for an article on microservices failure modes.
1. Cascading failures and circuit breakers
2. Retry storms in distributed systems
3. Service mesh overhead vs. naked HTTP
4. Database connection pool exhaustion under load
5. Config drift across environments and deployment targets
Using angle #1 (cascading failures), create a 5-section article outline.
Write section 2 (circuit breakers) in a direct, technical tone. Under 200 words.
Every time you insert a review point between prompt and output, you reduce the blast radius of an early mistake.
Session management
Split, hand off, consolidate
Long conversations degrade gradually. Earlier context gets diluted. The model starts contradicting things it said 20 messages ago. The broad exploratory thinking from an early research phase bleeds into the execution phase where you need precision. None of this is dramatic — it's the kind of drift you notice after the fact when the output stops being quite right.
Splitting work across focused sessions helps. One for research, one for planning, one for execution. The value is that each session starts with a clean context window containing only what's relevant to its specific job — no noise from previous phases, no risk of the model reopening decisions that were already made.
The hand-off prompt is what makes this work in practice. "Based on what we discussed" is too vague. What actually works is being specific: the decision made, the constraints in place, and exactly what to produce next. The example in the diagram below shows what that looks like.
At the end of every long session, ask the model to compress it: what was decided, what's still open, what context a fresh session would need to pick up from here. Save that output, paste it at the top of the next session. The model has no persistent memory across sessions, but it's good at summarizing what's currently in context. Use that.
We chose approach B (async fraud check via SQS queue). Constraints: no new dependencies, stay in existing ECS setup. Decided: webhook handler returns 200 immediately, fraud check runs in background. Decided: failure in fraud check triggers a separate retry queue, not webhook retry. Open: error handling if SQS is unavailable during fraud check submission. Output: TypeScript implementation of updated webhook handler. Do not add tests yet.
A session summary is a portable save file. Write it at the end of every significant session, before you close the tab.
Temperature and sampling
Controlling randomness
Temperature controls how the model samples from the probability distribution it computes at each step. At zero, it always picks the highest-probability token: deterministic, consistent, useful for code, classification, and factual extraction. As temperature increases, lower-probability tokens get a real chance of being selected. Output becomes more varied and sometimes more creative, but errors and hallucinations increase with it.
The rough starting points: low (0 to 0.2) for accuracy-critical tasks where getting the same answer twice is a feature; medium (0.3 to 0.7) for writing and planning where some variation is acceptable; high (above 0.8) when you specifically want unexpected combinations — brainstorming, ideation, creative writing. These are guidelines, not fixed rules.
Most consumer tools don't expose temperature directly. But understanding the mechanism helps with prompting. A prompt phrased so there's one clearly correct answer behaves similarly to low temperature — it collapses the distribution by constraint rather than by parameter. Open-ended framing has the opposite effect.
"Grounds & Co." — clean and versatile "The Press" — minimal, appeals to specialty crowd "Common Cup" — approachable, everyday feel
Temperature controls the tradeoff between consistency and variety. There's no universally right setting — it depends on whether getting the same answer twice is a feature or a bug.
Self-consistency, priming, meta prompting
The last 10%
Self-consistency is running the same prompt multiple times and taking the most common answer. A single chain of reasoning can go wrong early and produce a confident, wrong answer with no visible error signal. Three independent runs that all agree are harder to fool. This costs more tokens and is slower, so it's only worth it when getting the answer wrong has real consequences — math, multi-step logic, anything where a plausible-sounding error is expensive.
Output priming means giving the model the first few words of the response you want. Instead of "summarize the key risks," you write "summarize the key risks. Begin with: 'Three primary risks:'" The model continues from where you started it, rather than choosing its own opening. The model's choice of opener is one of the highest-variance parts of generation. Priming eliminates that variance with one short instruction.
Meta prompting is asking the model to rewrite your prompt before you run it: "Here's a draft prompt. Improve it for clarity, output format, and what to avoid." LLMs have seen a large volume of prompts and outputs during training, which gives them reasonable pattern-matching on what prompt structures tend to produce better results. A meta-prompting pass before a high-stakes task often surfaces gaps you glossed over when writing it quickly.
Q: A store sells apples at $1.20, $1.80, and $2.40 per pound. If you buy 2 lb of each, what is the total cost? [run once → answer: $10.80] [one chain of reasoning, one potential error point]
[run the same prompt 3× independently] → Run 1: $10.80 → Run 2: $10.80 → Run 3: $11.40 Most frequent: $10.80 ✓ (single-run confidence: 67% → ensemble: 90%+)
mechanism
Statistical majority vote across multiple reasoning paths reduces single-path error propagation. One path can go wrong early and produce a confidently wrong answer with no visible error signal. Three paths polling the same result are much harder to fool.
when to use
Math, logic, multi-step reasoning, any calculation where a confident wrong answer has real cost. The token overhead is real — only use it when accuracy matters more than speed.
These three techniques are worth learning after you've got the basics working. Trying to use self-consistency before you've sorted your constraints is just spending more tokens on a broken prompt.
The complete checklist
One page, everything you need
All seventeen techniques are pointing at the same thing: every ambiguous instruction is a roll of the dice. The model doesn't have opinions — it has probabilities. What we call context engineering is just the practice of reducing the number of guesses the model has to make before it can produce something useful.
0/ 17 complete
Verify everything. The model generates plausible text — not accurate text. This is not a solvable problem; it is a fundamental property of how these systems work.